
Решения / Речевая аналитика на основе ML-технологий Yandex SpeeckKit, или на основе открытых ASR моделей, с поддержкой казахского языка
Облачный Yandex SpeechKit понимает 16 языков, включая русский, казахский и узбекский языки. Для обучения моделей распознавания и повышения качества распознавания речи разработчики Yandex Cloud используют тысячи часов аудио для каждого языка.
ASR (Speech-to-Text) решение может быть развернуто в вашей инфраструктуре, для обеспечения приватного распознавания голос в текст. Предлагаемое нами решение с высоким качеством распознает речь на казахском языке, а также смешанную речь на казахском и русском языках.
Демонстрационный стенд решения доступен по ссылке.
Области применения речевой аналитики
Аналитика полезна для всех компаний, работающих с клиентами, но особенно эффективна речевая аналитика в сферах, где количество звонков особенно велико: банки, страховые компании, интернет-магазины, медицинские центры, службы доставки, различные call-центры.
- Контроль скриптов - контроль соблюдения скриптов продаж, регламентов и стандартов телефонного общения.
- Анализ недовольства - выявление случаев недовольства клиентов.
- Выявление потребностей - выявление и систематизация потребностей клиентов.
- Накопление данных - Накопление исторических данных по коммуникациям с клиентами, для последующего использования, например, для аналитики по новым критериям, или для обучения ИИ бота.
Слайды презентации речевой аналитики на основе Yandex SpeeckKit:

Для чего нужная речевая аналитика
Речевая аналитика позволяет контролировать 100% телефонных звонков, и автоматически оценивать качество работы специалистов компании, оценивать соблюдение регламентов и стандартов телефонного обслуживания. Так же аналитика позволяет быстро реагировать на недовольных клиентов, выявлять причины отказов клиентов.
Использование речевой аналитики помогает:
- Сократить затраты и расходы бизнеса на оплату труда;
- Сократить время на обучение новых сотрудников.
- Повысить объемы продаж;
- Проактивно реагировать на недовольных клиентов;
- Улучшить коммуникации с клиентами и повысить их лояльности к компании;
Как работает речевая аналитика
Решение «Речевая аналитика» развертывается на сервере Заказчика, или в облаке. Решение интегрируется с телефонией Заказчика, получает голосовые записи разговоров отдела продаж, или контакт центра. Далее решение переводит речь в текст и выполняет анализ текста, на предмет соблюдения скриптов разговоров, выявляет негатив, запрещенные слова, слова-паразиты. Далее решение формирует отчеты, рассчитывает рейтинг сотрудника, строит отчетность по сотруднику или по всему подразделению.
- Интеграция с телефонией - получает голосовые записи разговоров из телефонии, переводит речь в текстовые сообщения.
- Анализирует текст - выполняет поиск по тексту, по словарям, и фрагментам скриптов разговоров.
- Формирует отчеты - расчитывает рейтинг операторов, строит отчетность и график, по оператору или по всей группе.
Видео обзор речевой аналитики на основе Yandex SpeeckKit:
Количественный анализ
Количественный анализ текста фокусируется на числовых данных и статистике, чтобы оценить текст с точки зрения измеримых характеристик. Основная цель — объективно измерить определённые элементы текста, такие как слова и словосочетания, без осмысления их значений.
Для поиска слов и словосочетаний допускается использовать символы:
- «*» - любое окончание слова в словосочетании.
- «<>» - слова в словосочетании поменять местами.
- «/» - варианты слова в словосочетании.
Например, шаблон «добрый<>день/вечер» выполняет поиск четырех вариантов словосочетания:
- добрый день
- добрый вечер
- день добрый
- вечер добрый
Содержательный анализ
Содержательный анализ текста с использованием классификаторов GPT позволяет глубже понять и структурировать текстовые данные, выявляя темы, паттерны и категории. Модель GPT, обученная на обширных данных, классифицирует текст по заданным категориям, например «Новизна продукта», «Создание срочности», «Подведение итогов».
Для обучения GPT классификатора создается набор данных (dataset) из «правильных» реплик, в количестве не менее 100 реплик, рекомендуется до 10000 реплик. Например, для обучения GPT классификатора «Создание срочности» из накопленных диалогов сотрудников выбираются реплики:
[
{
"Про этот товар часто спрашивают. У вас точно нет возможности приехать в ближайшее время? Завтра этого товара может не быть в наличии."
},
{
"Условия кредитования меняются каждый месяц. Вы можете потерять выгодное предложение, если отложите покупку на потом."
},
{
"Если мы не успеем оформить заказ для вас в ближайшее время, то придется потом ждать следующую поставку, а это очень долго.",
}
]Далее, обученный классификатор GPT оценивает новые диалоги, и выделяет те, которые по смыслу близки к смыслу «правильных» реплик.
Видео - GPT классификаторы в отделе продаж:
Из каких разделов состоит аналитика
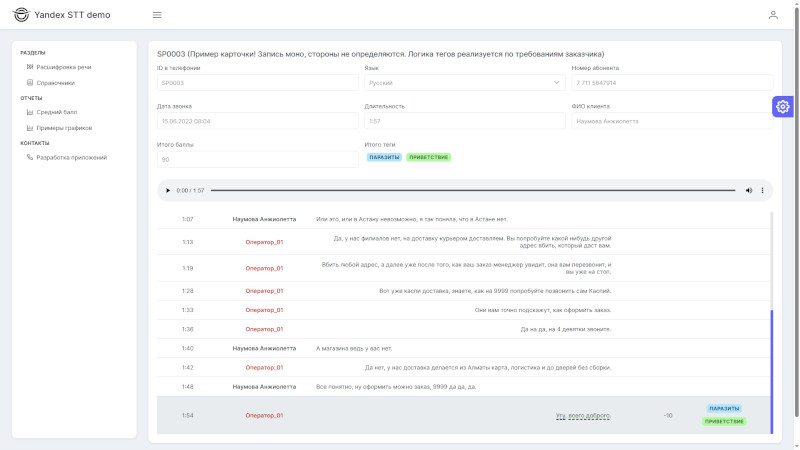
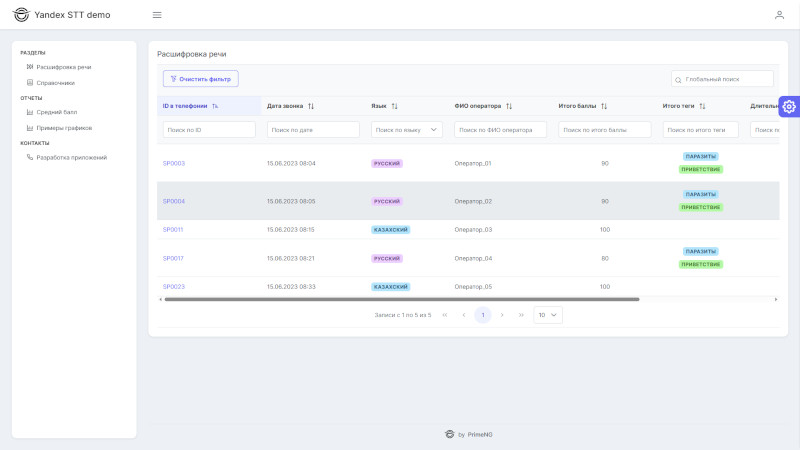
Раздел «Расшифровка речи»
Возможность прослушать голосовые записи из телефонии, с расшифровкой разговора. По клику на реплике диалога переход на соответствующую метку в аудиозаписи.
Найденные совпадения по словарям, и результаты проверки скриптов разговоров, подсвечиваются тегами в тексте диалога.
Статистика по разговору, оценка темпа речи, паузы, прерывал ли менеджер клиента.
Возможна интеграция с CRM системой Заказчика, для перехода на лид или сделку в CRM.
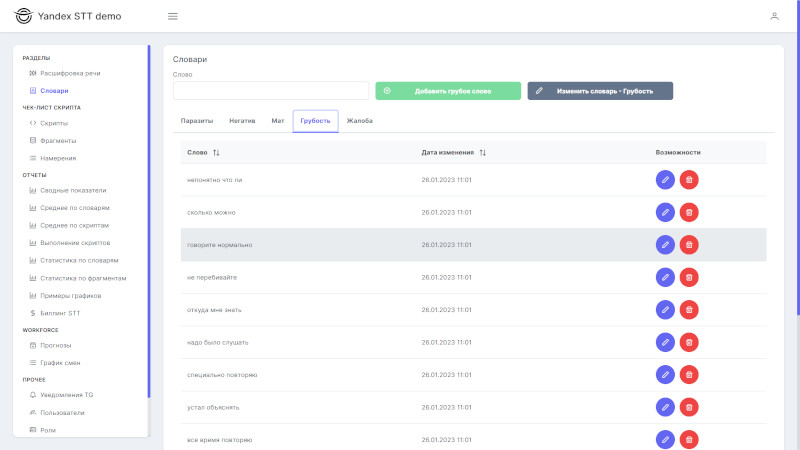
Раздел «Словари»
Управление словарями, удаление или добавление слов. Загрузка списка слов в словарь, из текстового файла.
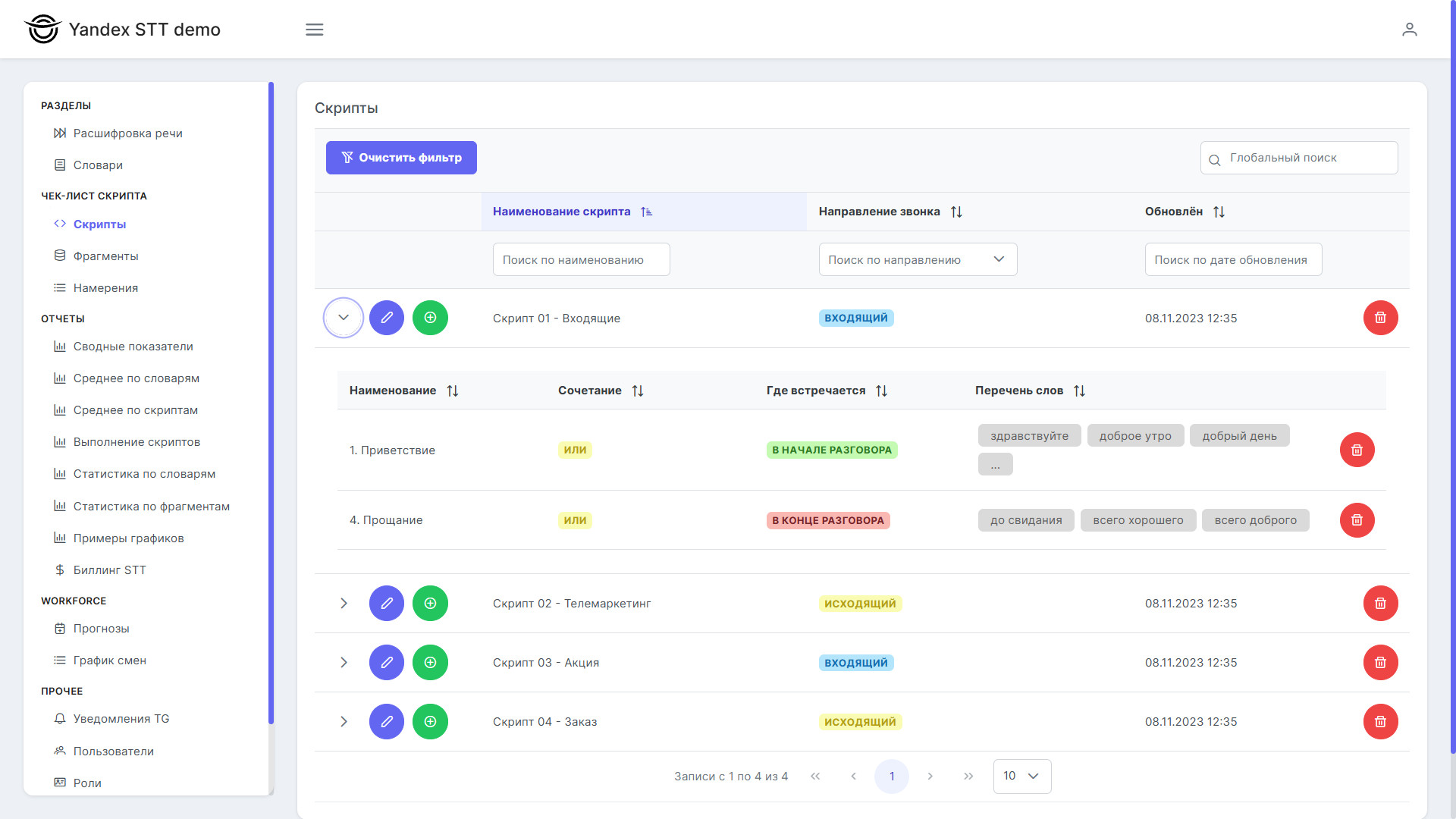
Раздел «Скрипты»
Управление фрагментами, редактирование фрагмента, удаление или добавление слов в фрагмент.
Управление скриптами, редактирование скрипта, удаление или добавление фрагментов в скрипт. Настройка параметров скриптов, назначение скриптов для групп операторов или подразделений.
Раздел «Отчеты»
Отчет «Сводные показатели» - анализ диалогов за период, общая статистика по диалогам.
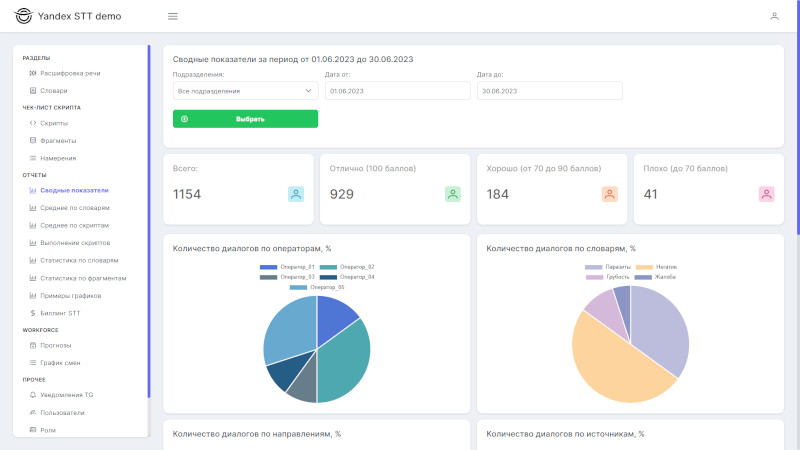
Отчет «Средний балл по словарям» - анализ работы менеджеров за период, сравнение оценок за словари по менеджерам.
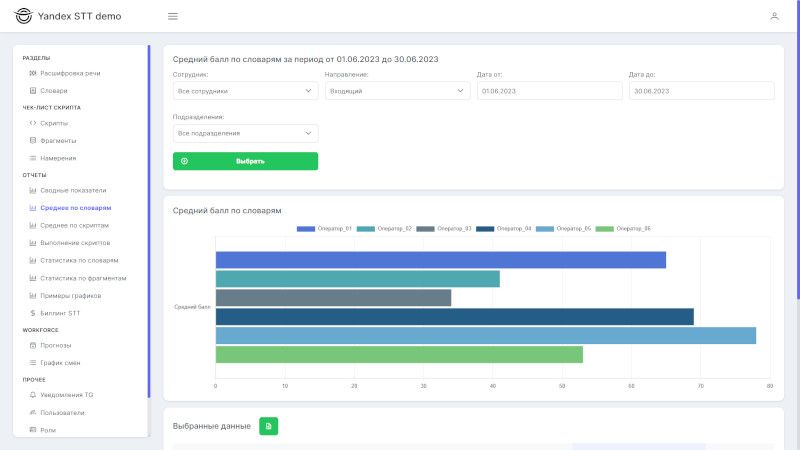
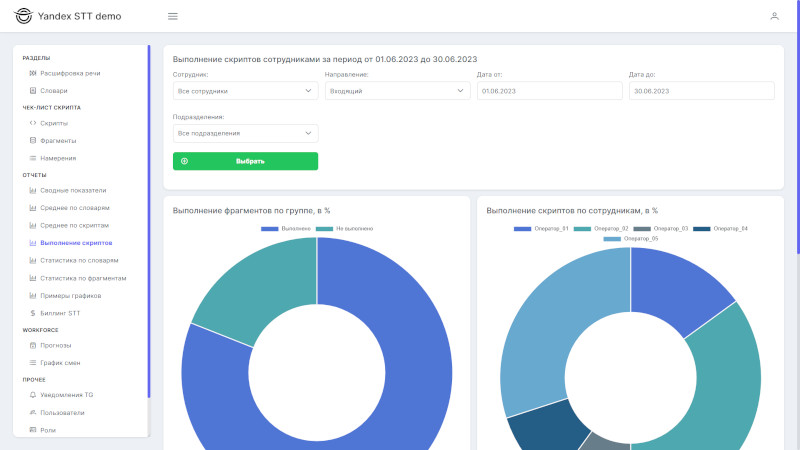
Отчет «Выполнение скриптов сотрудниками» - анализ выполнения скриптов менеджеров за период, сравнение оценок за скрипты по менеджерам.
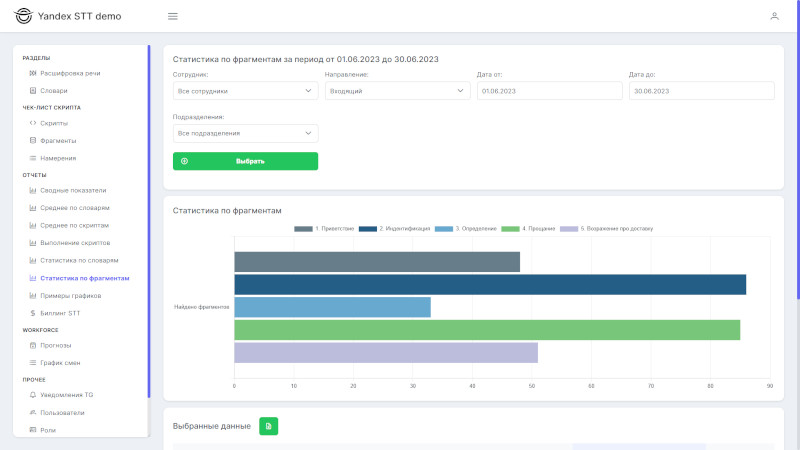
Отчет «Статистика по фрагментам» - анализ найденных совпадений фрагментов из скриптов в диалогах. Ранжирование наиболее частых совпадений.
Отчет «Биллинг STT» - анализ затрат на распознавание речи в текст.
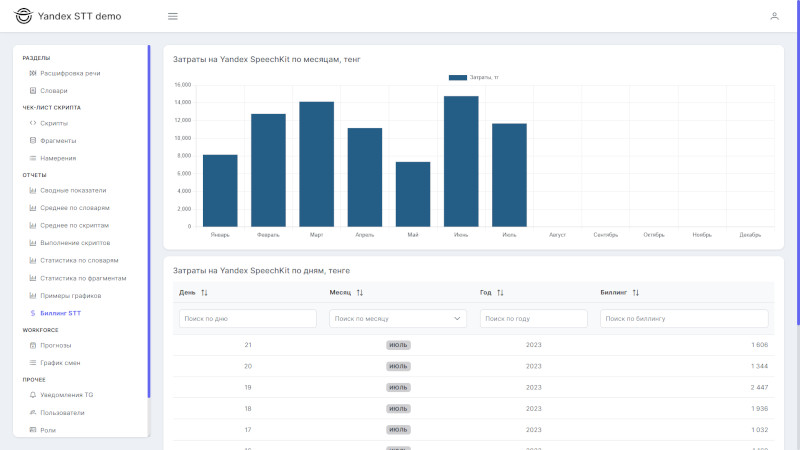
Раздел «Прочее»
Уведомления в Телеграм - история отправки уведомлений в Телеграм, о найденных совпадениях слов из критичных словарей, например, из словаря «Жалоба».
Пользователи и роли пользователей в системе, права на доступ к разделам, права на редактирование.
Служебный журнал системы, логи по распознаванию речи, сообщения о технических ошибках.
Рекомендации — персональный аудит навыков продаж
Раздел выполняет роль методиста по продажам. Система автоматически выявляет слабые места каждого менеджера и формирует персональный отчёт с конкретными рекомендациями — без субъективных оценок руководителя.
Как это работает:
- Формирование эталона — руководитель отдела продаж вручную отбирает лучшие диалоги из раздела «Звонки» и добавляет их в «Избранное». Это и есть эталон — не абстрактный учебник, а реальные звонки сильных менеджеров этой же компании, с этим же продуктом, этим же клиентам.
- Выявление слабых менеджеров — система анализирует оценки по чек-листу за период. Менеджеры со стабильно низкими результатами автоматически попадают в список для аудита.
- Gap-анализ — система случайно отбирает несколько диалогов слабого менеджера и сравнивает их с эталонными. Анализ проводится по трём блокам навыков.
- Формирование отчёта — по каждому менеджеру создаётся персональный отчёт «Рекомендации» с оценками, цитатами из диалогов и конкретным планом действий для руководителя.
Раздел оценивает навыки по трём блокам:
Блок А: Технология продаж (Hard Skills):
- Приветствие и вход в диалог — соблюдение регламента, идентификация и согласование цели звонка.
- Квалификация и выявление потребностей — умение задавать диагностические вопросы, а не просто консультировать по цене.
- Аргументация на языке выгод — формирование предложения исходя из потребностей клиента, а не перечисление характеристик товара.
- Отработка возражений — использование техник удержания клиента при сопротивлении («дорого», «я подумаю», «у других дешевле»).
- Закрытие на целевое действие — чёткий призыв к следующему шагу: визит, бронь, запись.
Блок Б: Коммуникативные навыки (Soft Skills):
- Управление инициативой — ведёт клиента по воронке или работает в режиме справочного бюро.
- Активное слушание — резюмирует слова клиента, реагирует на сигналы готовности к покупке.
- Работа с негативом — сохраняет конструктив при скепсисе и возражениях клиента.
Блок В: Предметная компетентность:
- Знание продукта — точность описаний, сравнение с конкурентами, ответы на технические вопросы клиента.
- Работа с ценой — обоснование стоимости, презентация условий, удержание клиента без скидок.
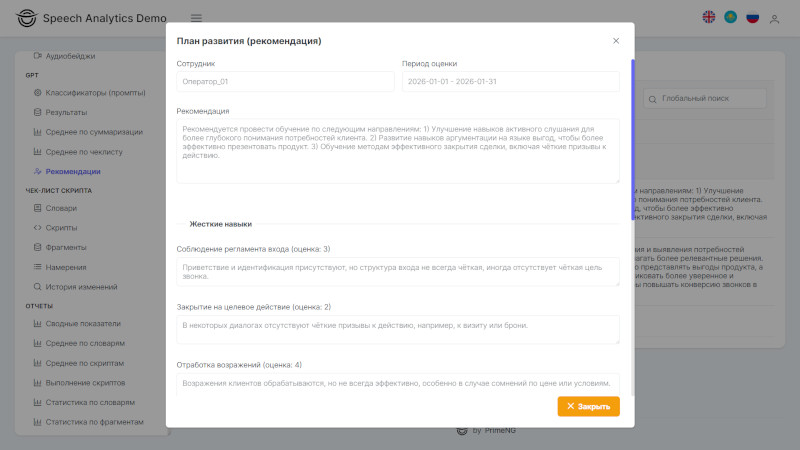
Итоговый отчёт «Рекомендации» — это не общий вывод «менеджер работает плохо», а конкретика: в каком навыке разрыв, как часто проблема встречается в диалогах, что именно сказал менеджер и как это должно звучать по эталону. Например: «Менеджер не предлагает целевое действие в 6 из 7 звонков. На ближайшей планёрке разобрать технику закрытия на примере диалога от 15 мая». Это позволяет руководителю сразу переходить к точечному обучению, не тратя время на поиск проблемных зон.
Интеграция с телефонией
Системе необходимо получить из телефонии данные о звонке (дата, время, подразделение, направление, и т.п.), а также файл аудио записи звонка. Аудио записи должны быть в формате стерео, каждая сторона разговора должна быть записана раздельно в левый и правый каналы стерео.
Если аудио записи в моно, например с микрофонов на рабочих местах, или с аудиобейджей, то при распознавании речи в текст система по голосу разделяет собеседников, но точность такого разделения порядка 70-80%, и зависит от качества записи микрофонов.
Возможны следующие варианты интеграции с телефонией:
Получение данных
Вариант 1. Данные о каждом звонке передавать в имени файла аудио записи звонка. Кол-во параметров в имени файла должно быть одинаковое как для входящих, так и для исходящих звонков. Символ разделителя параметров не может встречаться внутри самих параметров.
Например:
in-87771112233-Сергей Михайлов-Татьяна_Прохорова-101-20230726-093151-2914299-1690356110.6593244.mp3
В данном примере имя файла аудиозаписи состоит из девяти параметров, разделенных тире:
- in или out - признак, входящий или исходящий звонок;
- 87771112233 - номер телефона клиента;
- Сергей Михайлов - имя клиента;
- Татьяна_Прохорова - имя менеджера;
- 101 - id подразделения менеджера;
- 20230726 - дата звонка;
- 093151 - время звонка;
- 2914299 - id сделки в CRM (лида);
- 1690356110.6593244 - id звонка в телефонии;
Вариант 2. Предоставить аналитике прямой доступ в базу данных телефонии, учетная запись только для чтения. Аналитика забирает данные о телефонных звонках за последний час, или день.
Вариант 3. Реализовать веб сервис (REST + JSON) связанный с телефонией. Рекомендуется сделать два метода в таком веб сервисе. Первый метод это список всех звонков за период, например за последний час, или последний день, отсчитывая от момента запроса. Список содержит уникальный ID каждого звонка, например Uniqueid. Второй метод это детальная информацию о звонке, в ответ на запрос по ID звонка. При такой интеграции система аналитики с каким то интервалом, раз в 10 минут, или раз в час, запрашивает первый метод, получает список всех последних звонков за период, и определяет, какие из звонков уже загружены в систему, какие еще нет. Затем система аналитики через второй метод, по ID звонка, получает детальную информацию о звонке.
Получение файла с аудио
Вариант 1. FTP доступ в папку с аудио записями. Система аналитики по FTP подключается к папке с аудио записями, и по ID звонка находит файл с таким же ID в имени файла. Внутри основной папки можно разделить подпапки по месяцам и дням.
Вариант 2. Если сервер с речевой аналитикой находится в одной локальной сети с сервером телефонии, то возможно смонтировать папку с записями с сервера телефонии, на сервер аналитики. В этом случае аналитика будет обращаться к папке с аудиозаписями как к обычной папке в файловой системе своего сервера.
Вариант 3. Реализовать веб сервис (REST + JSON) связанный с телефонией, для получения файла аудио записи, по прямой ссылке, с помощью GET или POST запроса. В URL запроса, или в теле запроса, передавать ID файла, который нужно получить.
Мобильный клиент
Мобильный клиент (Android, iOS) отображает ключевые показатели и графики для компаний, пользующихся аналитикой от Sanatel. Приложение предоставляет быстрый доступ для руководителей, к основным показателям из речевой аналитики, внедренной в компании. Безопасность данных обеспечивается за счет того, что в приложение передаются только агрегированные данные за день, без детализации.
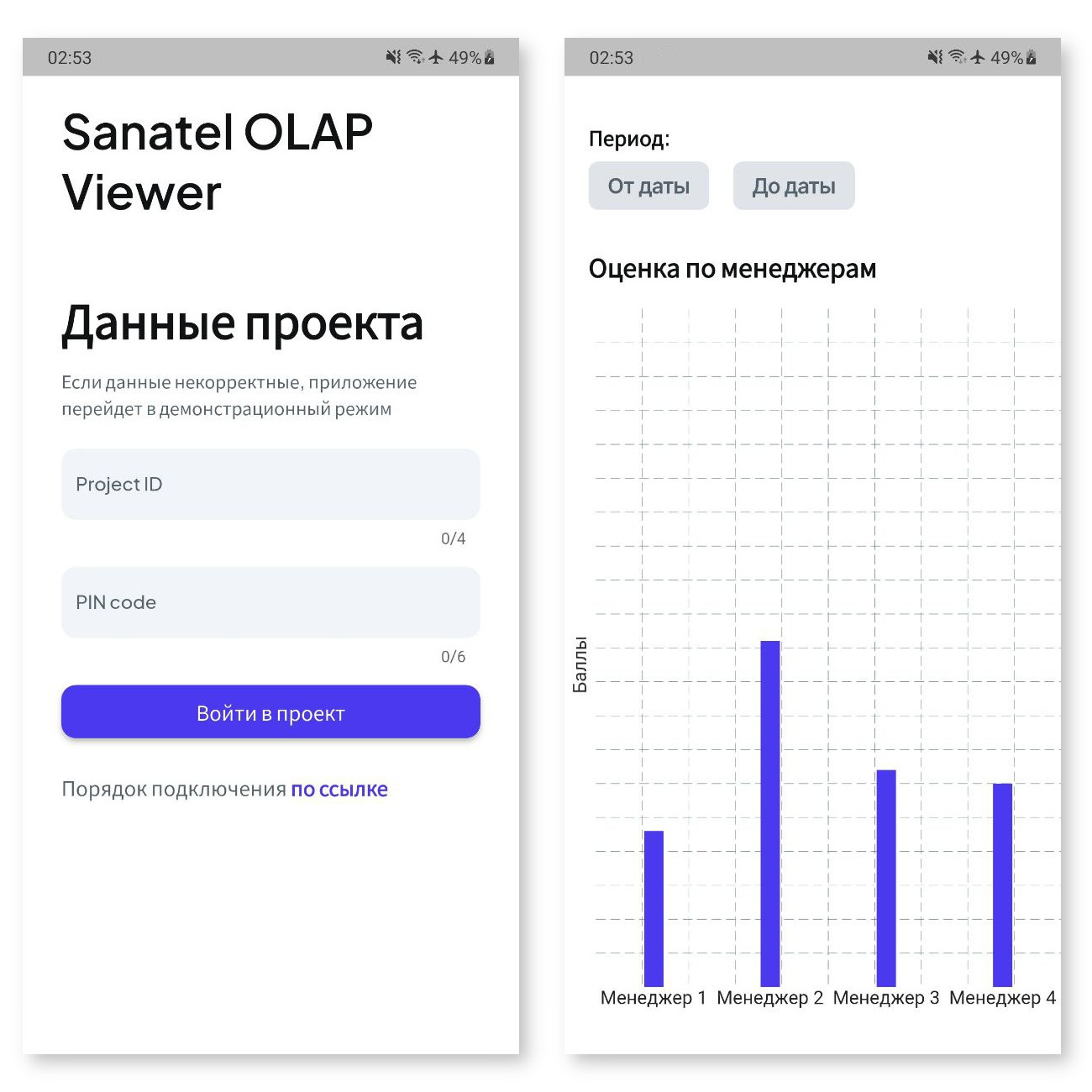
Дальнейшие перспективы после внедрения речевой аналитики
Речевая аналитика накапливает данные по коммуникациям компании с клиентами. В будущем большой объем накопленных данных может быть использован для обучения голосового бота компании.