
Статьи / Rasa: разработка, основанная на диалоге - итерация по ключевым показателям эффективности
21.04.2024 г., перевод статьи из блога Rasa, Alan Nichol
Уникальные возможности, открывающиеся при разработке диалогового ИИ, заключаются в том, что клиенты напрямую говорят то, что они хотят сделать или получить.
Наша цель — воспользоваться этой информацией и создать отлаженный процесс, в результате которого ИИ станет лучше понимать потребности клиентов, мы узнаем больше о своих пользователях, а виртуальный ассистент сможет помогать большему количеству людей в самых разных ситуациях.
Чтобы запустить процесс, группа, работающая над ассистентом, должна знать, за какие ключевые показатели эффективности она отвечает, а кроме этого, ей необходима постоянная обратная связь, показывающая, как вносимые ею изменения влияют на эти ключевые показатели эффективности.
В этой статье, посвященной CDD (разработке, основанной на диалоге), рассматриваются лучшие практики итераций и создания возможностей для улучшения бота.
Выбор KPI
Какие ключевые показатели эффективности необходимо отслеживать, чтобы определить успех продукта? Истинная ценность метрик проявляется со временем, и скорее всего вы не сможете измерить некоторые из ключевых показателей эффективности до тех пор, пока не будут достигнуты определенные этапы и не будет создана инфраструктура. Самое главное — выработать привычку систематически отслеживать KPI и оценивать усилия по их достижению. Не пытайтесь сразу выбрать какой-то идеальный показатель — вместо этого выберите 5–10 подходящих и сосредоточьтесь на формировании полезной привычки ориентироваться на них.
Ценность ИИ-помощника для бизнеса чаще всего определяется запаздывающими показателями. Запаздывающие показатели — это те, которые можно измерить только развернув бота для реальных пользователей. Вот некоторые распространенные KPI:

Первые два можно измерить автоматически, а третий и четвертый потребуют обратной связи от пользователей. Оба типа дополняют друг друга, и будет полезно учитывать по одному из них, тем более что на вопросы обратной связи обычно отвечает только небольшой процент пользователей.
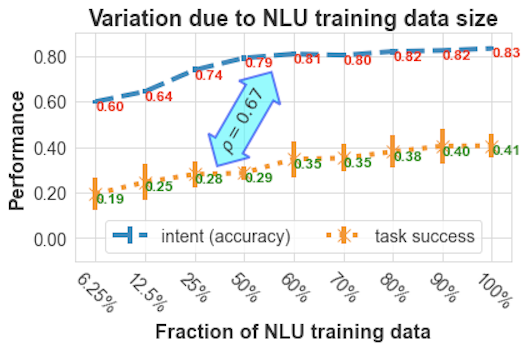
Опережающие показатели — это показатели качества ассистента, которые также можно оценить без привлечения реальных пользователей, то есть вы можете получить их в новой версии ИИ-ассистента, прежде чем запустить его в работу. В разделе ниже, посвященном показателям оценки NLU, приведены примеры. Опережающие показатели — полезное средство обратной связи во время цикла разработки. Диаграмма показывает соотношение характеристик между производительностью NLU и успешностью выполнения задачи в рамках одного бота.
Связь между релизами и улучшениями
Любой член команды должен быть в состоянии сказать: «В нашем последнем релизе мы работали над улучшением X, с результатом Y». Крайне важно, чтобы у команды была постоянная обратная связь: без нее им остается только гадать.
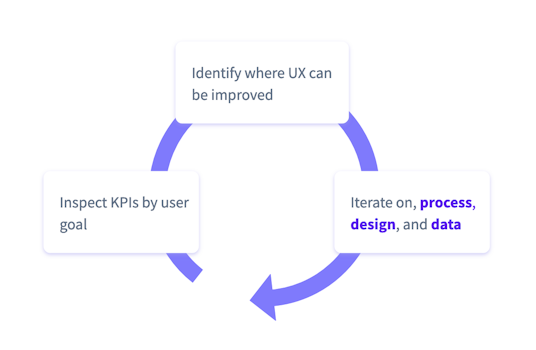
В каждом конкретном спринте вы сосредоточены на улучшении 1–2 областей ассистента. Чтобы увидеть результаты усилий, необходимо иметь возможность просматривать детализацию ключевых показателей эффективности с разбивкой по различным целям пользователей, реализованным в боте.
В конце спринта вы добавите в бот улучшения, и любой член команды должен четко понимать, каким будет ожидаемый результат. Здесь особенно важна детализация: инкрементное изменение может бесследно раствориться, если объединить его со всеми другими целями пользователя.
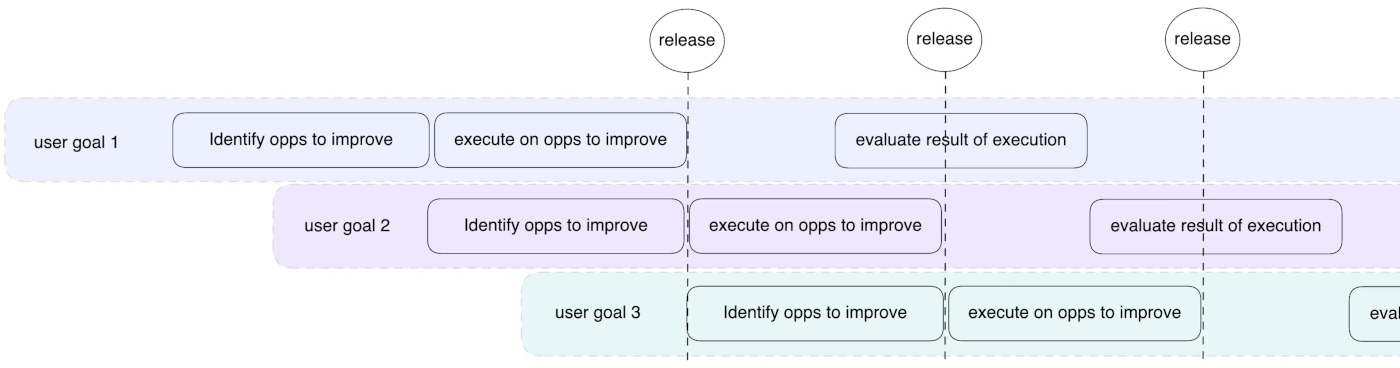
Конкретные инструменты, используемые для контроля истории изменений, планирования спринтов и определения приоритетов работы, могут различаться, в зависимости от предпочтений команды. Независимо от этого, владелец продукта (Product Owner) в любом случае обязан наладить процесс, подобный тому, что показан ниже, особенно на заключительном этапе, когда необходимо оглянуться назад и определить, принесли ли усилия предыдущего спринта желаемый эффект.
Двойной бэклог
Каждый ИИ-ассистент формирует модель мира: что могут говорить пользователи, какие темы существуют, какие функции поддерживаются, а какие нет. В заключительной статье этой серии мы обсудим модели мира более подробно. Один из компонентов, который мы уже рассмотрели — это таксономия намерений.
Для успешной разработки ассистента на базе искусственного интеллекта вам потребуется два отдельных бэклога. Один бэклог должен быть посвящен итеративным изменениям, а другой — радикальным, требующим модификации модели мира. Например, добавление нескольких новых обучающих примеров для улучшения эффективности одного из намерений — это небольшое итеративное изменение. Если вместо этого вы решаете, что вам нужно разделить намерение на две части — это радикальная перемена, которая требует изменения модели мира и, следовательно, также требует коммуникаций внутри команды. В таблице ниже приведены примеры обоих типов изменений.
Независимо от того, анализируете ли вы диалог или просматриваете результаты оценки NLU, при желании вы всегда найдете возможность внести изменения для улучшения ИИ-ассистента. Некоторые из них будут итеративными, некоторые — радикальными. Процесс внесения итеративных изменений обычно прост и легок — радикальные изменения по своей природе требуют больше усилий и к их планированию и реализации следует подходить с особой осторожностью.

Обеспечение качества и оценка
Обеспечение качества (QA / quality assurance) — это проверка того, что разработанное решение ведет себя именно так, как задумано. Оценка — это определение того, насколько решение эффективно в реальном мире. При работе с ИИ-ассистентом выполнять контроль качества можно, опираясь на то, что конкретные известные входные данные приводят к ожидаемым результатам, тогда как для оценки нужно определить, насколько хорошо модель будет работать с неизвестными входными данными.
Итерация данных: производительность модели NLU
Самое важное в итерации модели NLU — это убедиться, что ваша оценка соответствует реальному положению вещей. Я работал с командами, чьи боты обрабатывали почти миллион разговоров в месяц и которые считали, что точность их моделей находится на уровне 85%, когда реальная цифра составляла 41%. Вот что происходит, когда вы тестируете синтетические данные. Вы должны оценивать модель NLU на основе производственных данных — это не обсуждается.
Создание базы эталонных данных (Ground Truth)
Мы оцениваем качество модели NLU на основе того, как часто она делает правильный прогноз на пользовательское сообщение.
Для измерения нам потребуется база данных сообщений, которые пользователи отправили боту, а также Ground Truth, то есть правильные ответы. Ground Truth иногда называют Gold Label. Gold Label создается людьми, которые точно понимают конечного пользователя, а также таксономию намерений. Добавление Gold Label называется аннотацией.
Вкратце мы опишем процесс повышения эффективности работы с аннотациями, который подходит для крупных проектов с несколькими аннотаторами — если вы только начинаете, пока не думайте об этом. Возьмите образцы реальных сообщений, просмотрите и аннотируйте их. Выборка из 50 реальных сообщений — гораздо лучший способ оценки, чем полагаться на обучающие данные.
После того как вы аннотировали партию сообщений, можете упорядочить их по намерению, чтобы оценить производительность. В таблице ниже приведены некоторые из наиболее распространенных показателей, которые необходимо отслеживать. Эта оценка, хотя и выполняется вручную, является наиболее точным и надежным способом понять производительность модели. Кроме того, в результате вы постоянно пополняете базу данных Ground Truth — качественно аннотированных реальных сообщений пользователей. Эти данные будут полезны как для будущих оценок модели, так и в качестве источника обучающих данных для модели.
Показатели оценки NLU
Производительность для каждого намерения (интента):

Производительность для каждой сущности:

Расширенная процедура аннотирования
По мере роста обратной связи при развертывании новой модели, аннотировании сообщений и дополнении обучающих данных, получать максимальную отдачу от времени, затрачиваемого на аннотирование, становится все важнее.
Аннотация начинается с партии пользовательских сообщений вместе с прогнозами модели за определенный промежуток времени (например, за предыдущую неделю). Эта партия обычно фильтруется и отбирается, чтобы сохранить управляемость объемом данных:
- Вначале можете отфильтровать любые сообщения с точным совпадением в базе данных Ground Truth. У вас уже есть Gold Label для них, поэтому не нужно будет заниматься этим повторно.
- Затем отфильтруйте конкретные (прогнозируемые) намерения, связанные с фокусом текущего спринта.
- При необходимости можно отфильтровать по определенным диапазонам уверенности. (Внимание: если модель машинного обучения сообщает о высокой уверенности, это не означает, что это так и есть! Это видео — хорошее руководство по значениям уверенности.)
- Наконец, сделайте произвольную выборку, чтобы уменьшить общее количество сообщений.
Существуют и более продвинутые способы, но о них поговорим в других материалах.
Дополнение обучающих данных
Каждый раз, когда вы занимаетесь аннотированием, вы создаете новые обучающие примеры, которые затем можно использовать, чтобы научить модель NLU понимать, что на самом деле имеют в виду ваши клиенты. Итак, какие данные из Ground Truth базы данных должны стать частью обучающего набора? Тут есть над чем подумать — я видел, как команды разработчиков тратили уйму времени на обсуждение лучших эвристик для выборки данных. Но вам не нужно гадать! Теперь у вас есть два надежных способа оценки модели NLU:
- Сопоставить модель с базой данных Ground Truth и вычислить, насколько часто ее прогнозы оказываются верными.
- Создать следующую партию аннотаций (после развертывания) и подсчитать, насколько часто прогнозы оказываются верными.
Любое интуитивное представление о том, что следует, а чего не следует включать в обучающие данные, можно быстро и объективно проверить.
Итерации дизайн-процесса
Недавно я встречался с корпоративной командой разработчиков, чей бот работал неэффективно. В начале рабочей сессии я спросил их: «Расскажите мне немного о вашем текущем опыте работы с пользователями. Какие цели пользователей достигаются успешно, а какие — нет? Где возникают самые большие проблемы в UX?». В ответ они показали мне проектную документацию и бизнес-логику бота. Я попробовал спросить еще раз: «Нет, я хочу увидеть, как пользователи взаимодействуют с вашим ботом. В чем заключаются возникающие проблемы?». Они снова начали показывать детали, связанные с разработкой и технической реализацией.
В конце концов мне удалось донести свой вопрос, после чего мы начали вместе просматривать реальные разговоры с конечными пользователями. Чтобы понять, как работает бот, нужно выйти за пределы синтетических условий и оценивать реальные разговоры, которые происходят на самом деле, а не смоделированные вами.
Для того, чтобы это сделать, требуется как количественный, так и качественный анализ. Цель этой статьи — вооружить вас инструментами, необходимыми для изменения показателей KPI, но для этого нужна реальная оценка, а не просто цифры.
В отличие от веб- или мобильного приложения, в диалоговом ИИ мы видим расшифровку, которая дает уникальное представление того, что пользователь пытался сделать и где он застрял. Расшифровка никогда не раскроет полной картины — в конце концов, мы можем только догадываться о более широком контексте пользователя: где он находится, чем еще занимался — тем не менее мы получаем гораздо больше информации, чем, например, при анализе последовательности нажатий кнопок в приложении.
Реальные люди, в силу своей особенности, незаменимы при создании более эффективных и человечных ИИ-ассистентов.
Конверсационный анализ
Исходя из вышеперечисленных причин становится ясно, почему так важно, чтобы каждый член команды регулярно просматривал разговоры конечных пользователей. Как и в случае с аннотациями, начните с формирования привычки, а затем усовершенствуйте процесс. Владелец продукта (Product Owner) несет ответственность за внедрение этой привычки в команде — независимо от того, делается ли это индивидуально или в группе.
Просматривая разговоры, скорее всего, вы обнаружите много таких же ситуаций, что и во время прототипирования. Возможно, придется переписать подсказки, возможно, потребуется рефакторинг намерений, а может придется упростить базовую бизнес-логику. Когда вы находите зацепку для улучшения, возникает очевидный вопрос: «как часто происходит такая ситуация?». Добавление тегов к разговорам — один из способов отслеживать закономерности. Это позволяет владельцу продукта оценить влияние проблемы, а UX-разработчику — легко обнаружить соответствующие разговоры при редизайне конкретной ветки.
По мере расширения практики анализа разговоров можно применять многие эвристики фильтрации из раздела об аннотации NLU. Кроме того, вы можете сосредоточить внимание на анализе разговоров, в которых произошли или не произошли определенные события. Например, вы можете просмотреть беседы, в которых пользователи выразили определенное намерение, а в конце беседы дали негативный отзыв.