Статьи / YandexGPT и речевая аналитика: от поиска ключевых фраз — к пониманию смысла
17.09.2020 г., статья для блога на Habr
Речевая аналитика в контакт-центре, или в отделе продаж — это ключевой инструмент для оценки качества обслуживания и соблюдения стандартов общения. С развитием больших языковых моделей (LLM), таких как YandexGPT, подход к анализу диалогов кардинально изменился. Теперь вместо поиска словосочетаний и настройки сложных шаблонов — достаточно передать весь диалог модели и задать ей понятные вопросы.
Раньше аналитика работала по линейному сценарию: голосовые записи звонков из телефонии транскрибировались в текст, после чего специальный модуль искал в этом тексте заранее заданные ключевые слова и фразы. На основе наличия или отсутствия этих фраз делались выводы: был ли использован нужный скрипт, было ли приветствие, озвучено ли имя клиента и пр.
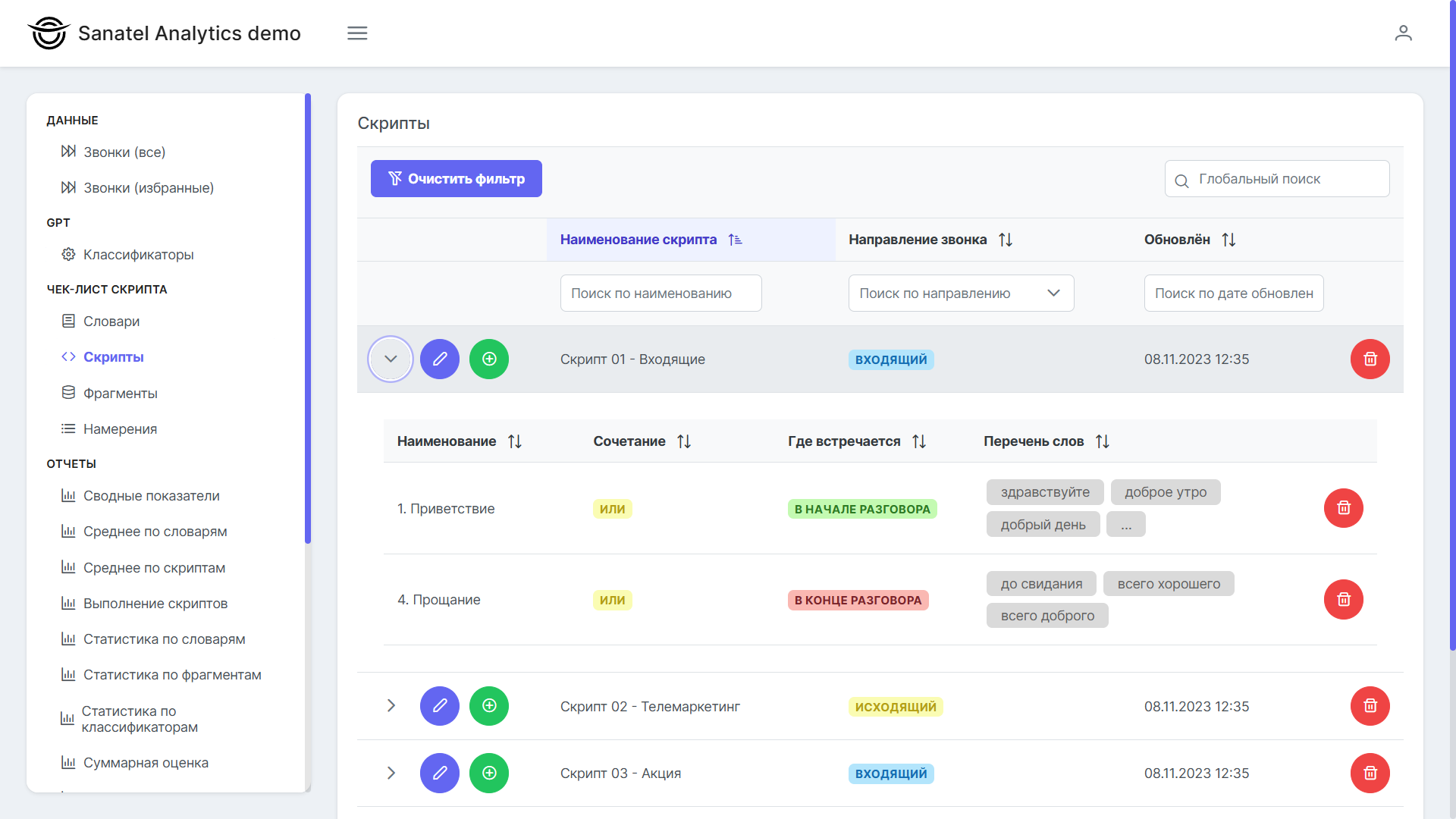
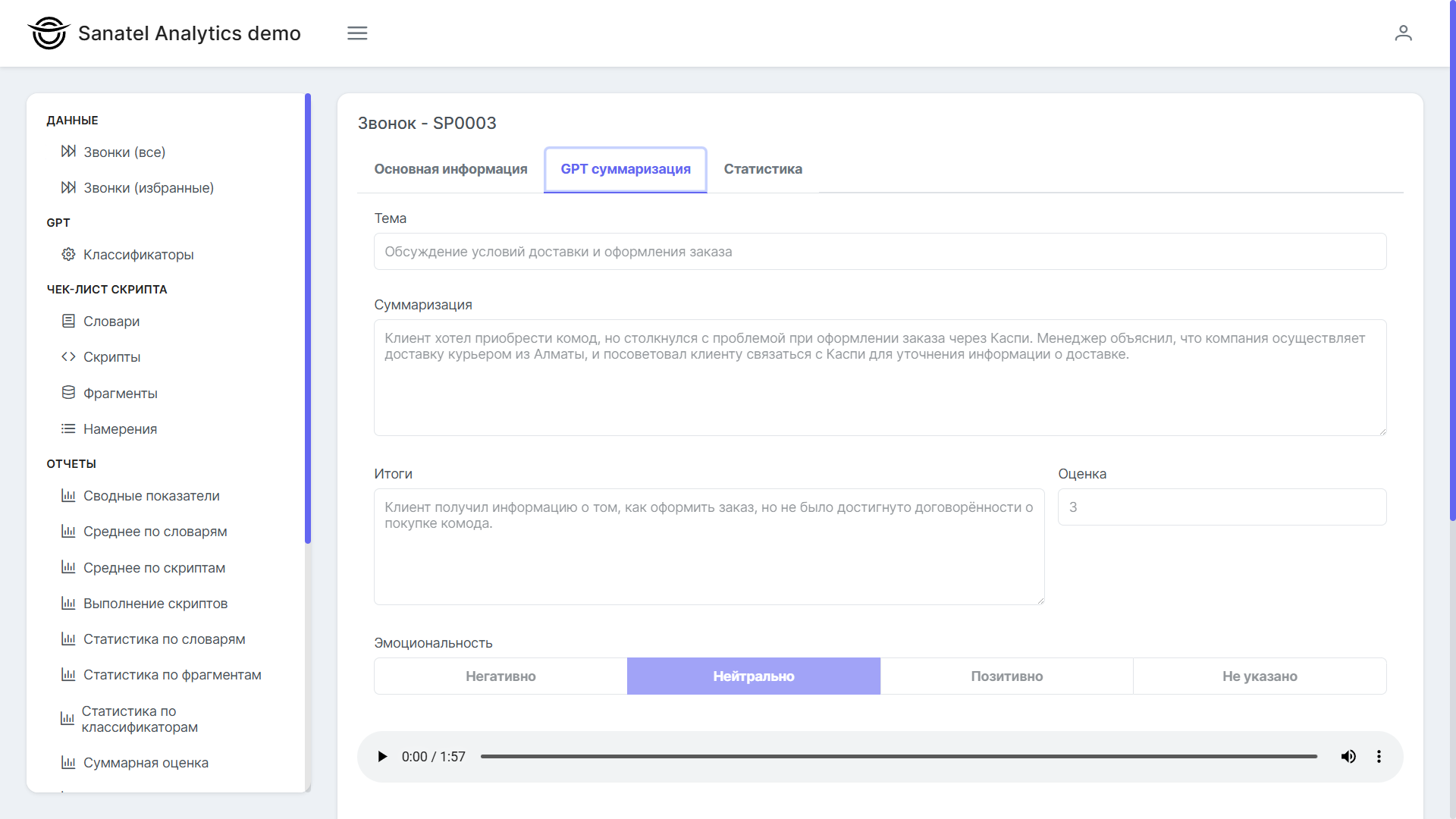
Теперь достаточно интегрировать аналитику с YandexGPT. Рассмотрим чуть более сложную аналитику, чем оценка «было ли приветствие». Оценим эмоциональность диалога (положительно, нейтрально, негативно), и пытался ли менеджер решить основную задач. Например, для автосалон, основная задача менеджера — пригласить клиента посетить автосалон. Еще желательно вылавливать случаи «Нет в наличии», когда клиент искал автомашину, которой нет в наличии.
Шаг 1. Собрать системный промпт
В запросе на API Яндекс есть два промпта, system и user. В системном промпте описываем общее задание для GPT, и добавляем описание, как результаты обработки разложить в JSON.
const mainPrompt = "Твоя компания продает автомашины. Ты аналитик, ты оцениваешь работу менеджеров отдела продаж. Оцени разговор менеджера с клиентом. Основной задачей менеджера является убедить клиента посетить автосалон.";
const jsonPrompt =
'Дай следующие результаты анализа:\n' +
'1. Тема разговора (результат в поле topic);\n' +
'2. Суммаризируй разговор (результат в поле summary);\n' +
'3. Подведи итоги разговора (результат в поле result);\n' +
'4. Поставь оценку менеджеру (от 0 до 5), пытался ли менеджер выполнить свою основную задачу (результат в поле rate);\n' +
'5. Сообщал ли менеджер клиенту, что какого-то товара нет в наличии: да (out), нет (nope) - (результат в поле stock);\n' +
'6. Оцени эмоции в разговоре: негативно (negative), нейтрально (neutral), позитивно (positive) - (результат в поле emotional);';Соединяем через точку оба промпта, получаем системный промпт:
const systemPrompt = mainPrompt + '. ' + jsonPrompt;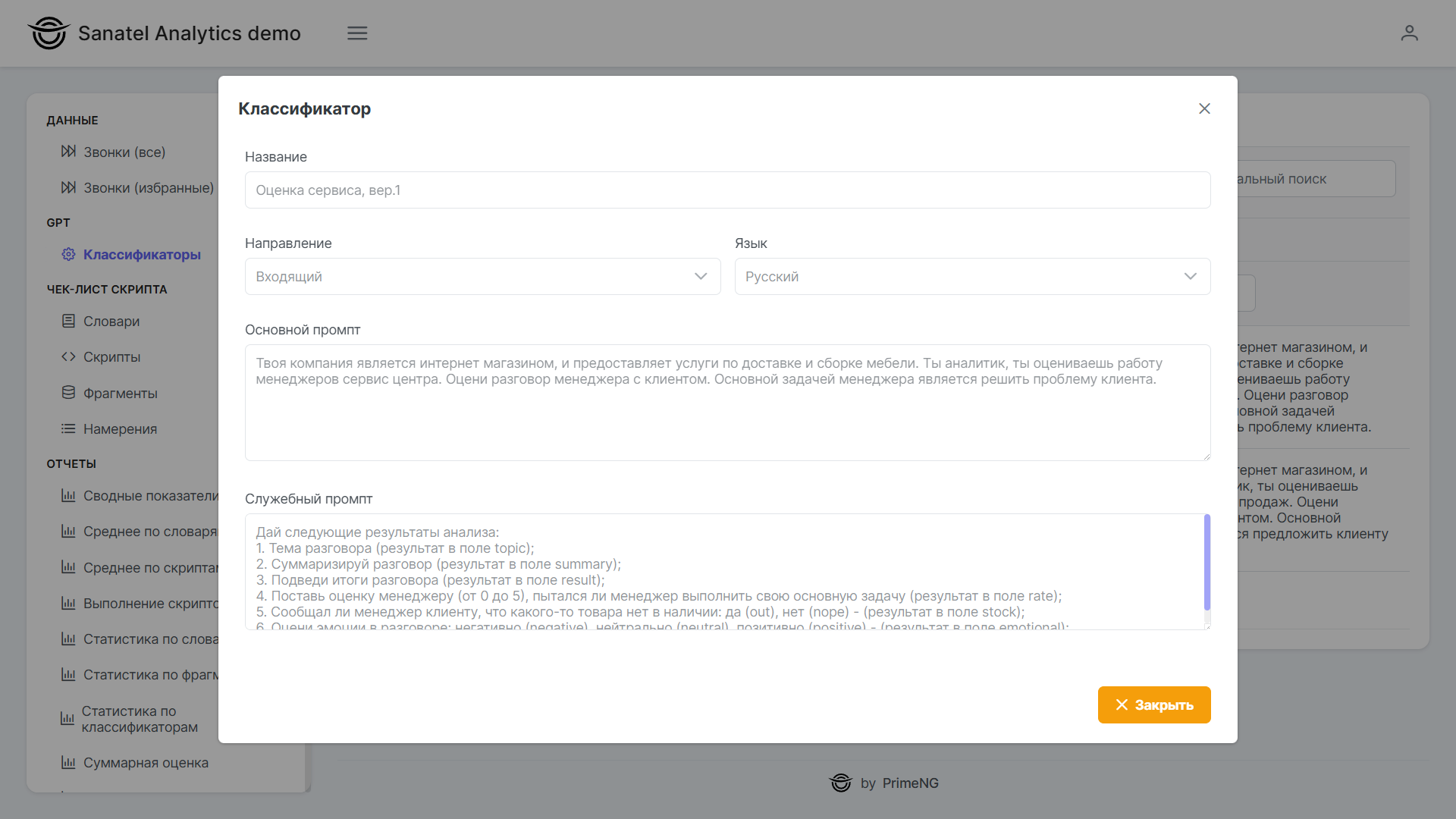
Шаг 2. Собрать данные по диалогу
Во второй промпт, который user, собираем простынь переписки. Автор реплики, и через двоеточие сама реплика. Следующая реплика через новую строку. Так как в системном промпте используются «Менеджер» и «Клиент», то соответственно в переписке тоже используем «Менеджер» и «Клиент», а не «сотрудник», «покупатель», или как то еще.
const userPrompt =
'Клиент: здравствуйте, меня интересует автомашина;\n' +
'Менеджер: да, есть автомашины, но в наличии осталось мало. Не хотите ли приехать в автосалон?;\n' + ...
Шаг 3. Отправляем запрос в YandexGPT
У YandexGPT в API есть несколько методов для работы с LLM, самый дешевый это асинхронный. Цены зависят от токенов. Если не в токенах, а в понятных единицах измерения, то оценка одного диалога (примерно 2-3 минуты разговор) будет стоить около 4-5 тенге за диалог, это порядка 1 руб за диалог.
Запрос отправляем на «штатную» LLM. Есть еще вариант дообучить модель, и работать со «своей» LLM, но для общей оценки диалога, достаточно «штатной» LLM.
Соответственно url для асинхронного запроса:
const urlYandex = 'https://llm.api.cloud.yandex.net/foundationModels/v1/completionAsync';Для запрос на API еще нужен folderId, это ID папки в консоли Яндекс. Так же в папке должен быть сервисный экаунт с ролью ai.languageModels.user, и для этого экаунта создать API-ключ.
Тело запроса:
const requestBody = {
"modelUri": "gpt://" + folderId + "/yandexgpt/latest", // "Это если испольуем общую LLM
// "modelUri": "ds://" + modelId, // Это если используем дообученную "свою" LLM
"completionOptions": {
"stream": false,
"temperature": 0.3,
// "maxTokens": "20"
},
"messages": [
{
"role": "system",
"text": systemPrompt,
},
{
"role": "user",
"text": userPrompt
}
],
"jsonObject": true,
"jsonSchema": {
"schema": {
"type": "object",
"properties": {
"topic": {
"type": "string"
},
"summary": {
"type": "string"
},
"result": {
"type": "string"
},
"rate": {
"type": "number",
"minimum": 0,
"maximum": 5,
},
"stock": {
"type": "string",
"enum": [ "out", "nope" ]
},
"emotional": {
"type": "string",
"enum": [ "negative", "neutral", "positive" ]
}
},
"required": [ "topic", "summary", "result", "rate", stock", "emotional" ] // Если не указать required, то LLM может игнорировать поля
}
}
}Выше, в системном промпте описано, как результаты оценки разложить в JSON. Соответственно в запрос вкладываем эту же самую JSON схему, и указываем, что поля обязательные (required). Если не указать required, то LLM может игнорировать поля.
При отправке запроса заголовок x-client-request-id можно не присваивать, он не влияет ни на что. Пустой заголовок x-data-logging-enabled означает, что я не хочу, чтобы Яндекс использовал мои данные для обучения своих моделей, то есть я не хочу, чтобы Яндекс хранил у себя мои данные.
По результатам запроса API должен вернуть resuestId, если тело корректное. Если некорректное, то в ответе не будет data.id.
let result = {
success: false,
state: 'dummy',
requestId: 'no',
}
axios.defaults.headers.common['Authorization'] = 'Api-Key ' + gptKeyAPI;
axios.defaults.headers.common['x-client-request-id'] = 'snt_' + UtilRandomNum( 10000000, 90000000 );
axios.defaults.headers.common['x-data-logging-enabled'] = '';
try {
const res = await axios.post(urlYandex, requestBody);
result.requestId = res.data.id;
result.state = 'gpt';
result.success = true;
return result;
} catch (e: any) {
result.success = true;
result.state = 'bad';
return result;
}Полученный requestId сохраняем.
Шаг 4. Получаем результаты YandexGPT
Далее через пару минут запрашиваем результаты, с url:
axios.defaults.headers.common['Authorization'] = 'Api-Key ' + gptKeyAPI;
const url = 'https://operation.api.cloud.yandex.net/operations/' + requestId;Если в ответе есть поле done, и в нем значение true, то результаты готовы.
Парсим результаты:
const responseString = response.data.response.alternatives[ 0 ].message.text;
const responseData: any = JSON.parse( responseString );В responseData будет JSON схема с ответом от YandexGPT.
Далее сохраняем, и показываем результаты пользователям в карточке звонка на вкладке «GPT суммаризация».