
Статьи / Размерные модели – логические или физические?
30.10.2018 г., перевод статьи Ralph Kimball
Размерные модели данных существовали в течение очень долгого времени, почти наверняка их происхождение восходит к первоначальному проекту Data Cube, затеянного Dartmouth University и General Mills в конце 1960-х годов. Привлекательность размерного моделирования проистекает из очевидной простоты моделей и естественного способа, с помощью которого как бизнесмены, так и технические специалисты могут понять, что означают модели.
Размерные модели имеют два совершенно разных выражения: логическое и физическое. Чисто логическим выражением является пузырьковая диаграмма.
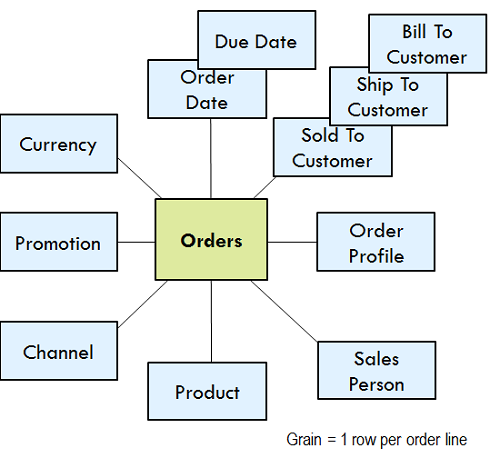
Поле в центре всегда представляет измерения событий, например, позиции строки заказа в примере. Мы называем это фактами. Пузырьки вокруг края представляют естественные размеры, связанные с измерениями событий. В логической модели пузырьковой диаграммы очень мало технического контента базы данных, но много бизнес-контента. После того, как источник измерения фактов был определен, логическая модель представляет собой хорошее решение, чтобы начать серьезный проект.
После согласования логическая модель пузырьковой диаграммы довольно быстро трансформируется в гораздо более конкретную техническую конструкцию, изобилующую именами таблиц, именами полей и объявлениями первичного ключа-внешнего ключа. Это то, что большинство ИТ-специалистов считают размерной моделью. Хм, это выглядит довольно физически. Когда этот физический дизайн был принят, кажется, что единственный оставшийся шаг – написать подробный DDL, создающий все целевые таблицы, а затем перейти к бизнес-реализации ETL-конвейеров для заполнения этих физических таблиц.
Подождите! Не так быстро! Если мы честны в отношении этой самой физической размерной модели, мы должны признать, что на истинном физическом уровне хранения наша размерная модель может быть реализована совсем по-другому. Две основополагающие вещи в этом случае – это столбчатые базы данных и виртуализация данных. Столбчатые базы данных кардинальным образом переставляют данные в сортированные и сжатые столбцы, сохраняя поверхностную иллюзию исходной размерной модели. Виртуализация данных преобразует фактические физические данные практически в любую оригинальную форму во время запроса, сохраняя при этом поверхностную иллюзию исходной размерной модели. Экстремальные формы виртуализации данных, популярные в мире Hadoop, иногда называют «отложенной привязкой» или «схемой при чтении». Но во всех случаях конечным результатом является знакомая размерная модель.
Вместо того, чтобы зацикливаться на общепринятых аргументах о логических и физических моделях, мы должны просто признать, что размерная модель на самом деле является интерфейсом программирования приложений хранилища данных (API). Сила этого API заключается в согласованном и едином интерфейсе, который видят все наблюдатели: как пользователи, так и BI-приложения. Мы видим, что не имеет значения, где хранятся биты или как они доставляются при запуске запроса API.
API размерной модели очень специфичен. Он должен предоставлять таблицы фактов, денормализованные таблицы измерений и суррогатные ключи для одного столбца. Запрашивающее приложение бизнес-аналитики не может и не должно заботиться о фактической реализации и доставке наборов результатов. Теперь мы видим, что истинная идентичность размерной модели – это API хранилища данных.