
Статьи / Как приручить событийно-ориентированные микросервисы
10.10.2020 г., перевод статьи Bernd Rücker
Этот пост изначально был опубликован на InfoWorld. Также недавно я выступал с докладом по этой теме на QCon NYC (Презентация).
Современные микросервисные архитектуры являются событийно-ориентированными, реактивными и придерживаются хореографического подхода (в противовес к централизованному контролю через оркестратор), что позволяет им быть слабо связанными и легко изменяемыми, не так ли?
TL;DR: А вот и нет! Вы столкнетесь с препятствиями связанными с пониманием и управлением потоком событий.
В этой статье я просуммирую свой опыт работы с хореографией микросервисов и укажу на различные препятствия и последствия данного подхода. Я использую типичный пример из бизнеса - процесс “клиентской адаптации” (в зависимости от отрасли, вы могли слышать о нем как об открытии счета). Для представленной очереди событий ниже, я использую Apache Kafka, но не беспокойтесь если используете другой стек, для него будут применимы все те же понятия.
Хореография микросервисов
Предположим, что следующие сервисы и события формируют вашу схореографированную систему:
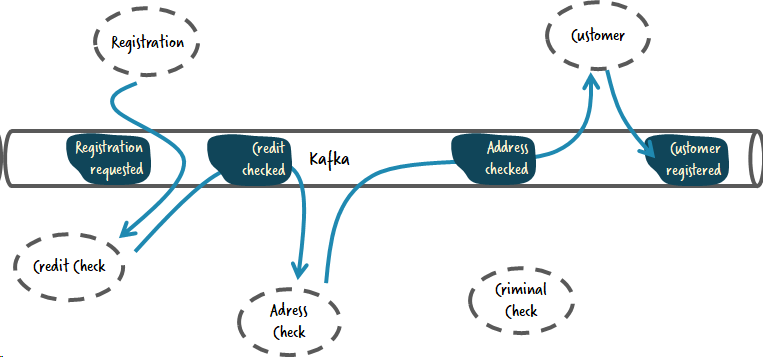
Главные препятствия возникающие при использовании данного подхода могут быть описаны следующими вопросами
- Как менять поток событий?
- Как избежать потерю наглядности потока? Как поддержать его понятность?
- Как управлять SLA и стойкостью общего потока? Как определить если что-то пошло не так? Как запустить повтор операции? Как улучшить систему?
- Как избежать жесткой связанности (например, необходимость знания о регистрации клиента при проверке на кредитоспособность)?
Начнем с рассмотрения первых двух пунктов и когда придет время, обратимся к оставшимся.
Изменение потока событий
Предположим, что вам необходимо добавить проверку на судимости. Основная идея схореогрефированных систем часто состоит в возможности добавления микросервисов без изменения чего-либо еще. Вы легко можете добавить сервис для проверки судимостей, который будет реагировать на определенные события, но для этого придется как минимум изменить сервис для работы с пользователями.
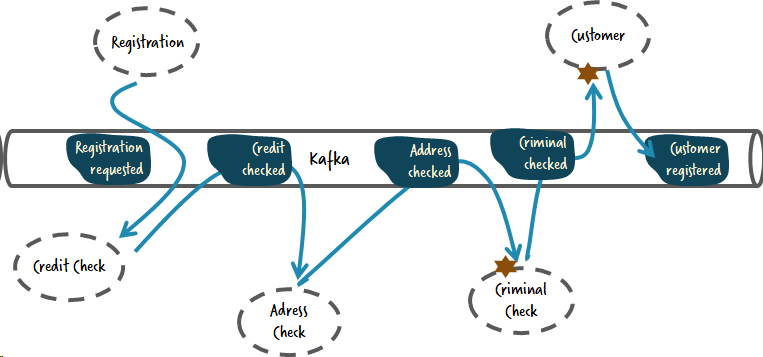
Таким образом ваша система оказывается не настолько свободно связанной как вы бы могли ожидать.
Обычно, люди сказали бы, что проиллюстрированный выше поток испорчен и необходимо его улучшить чтобы решить эту проблему. Попробуем альтернативное решение:
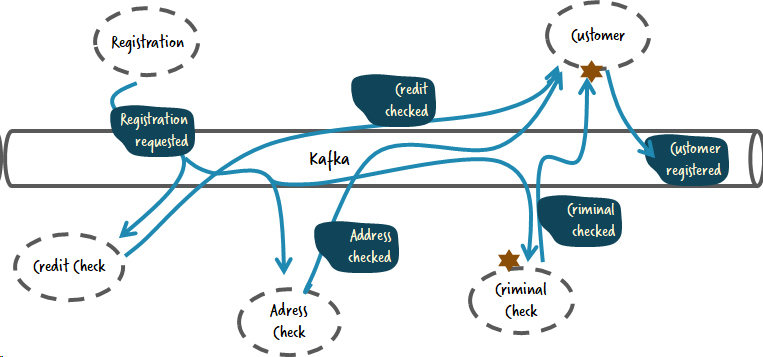
Теперь все сервисы работают в параллели и сервис для работы с клиентами ответственен за обработку всех событий. Но для того чтобы обработать результат проверки на судимости в клиентском сервисе, все еще придется изменить два других.
Не поймите меня неправильно. Я считаю, что изменения подобного рода неизбежны. Моя точка зрения состоит в том, что вы не можете избежать малой доли связанности в вашей архитектуре. Построение событийно-ориентированной системы не заставит эти требования испариться магическим образом.
Потеря наглядности?
Следующее препятствие состоит в понимании того, что происходит в вашей архитектуре. Событийно-ориентированные системы имеют "непредсказуемое поведение", опыт работы с которым можно получить только на практике, вы не сможете понять данный аспект просто проводя статический анализ кода. Стефан Тилков описал это как: “Что чёрт возьми сейчас произошло”, Джош Вульф писал: “Система, которую мы заменяем, использует пиринговую хореографию, которая требует знаний в различных кодовых базах для её понимания”. И наверное лучшее описание данной проблемы пришло от Мартина Флауэра в “Что вы имеете ввиду под ‘Событийно ориентированными’?”:
Оповещение о событиях это хорошо, потому что оно подразумевает низкий уровень связанности и его достаточно легко внедрить. Однако, это может быть проблематично если существует логический поток, зависимый от нескольких оповещений. Проблема состоит в том, что подобный поток проблематично заметить, так как он не представлен в коде. Часто, единственный способ определить его - это мониторинг системы в режиме реального времени, что может привести к сложности отладки и модификации. Также, опасность в том, что легко построить слабо связанные системы с оповещением о событиях, не заметив потерю наглядности более крупного потока и таким образом создать себе проблемы в будущем. Подытожив можно сказать, что паттерн все еще очень полезен, но стоит опасаться определенных ловушек.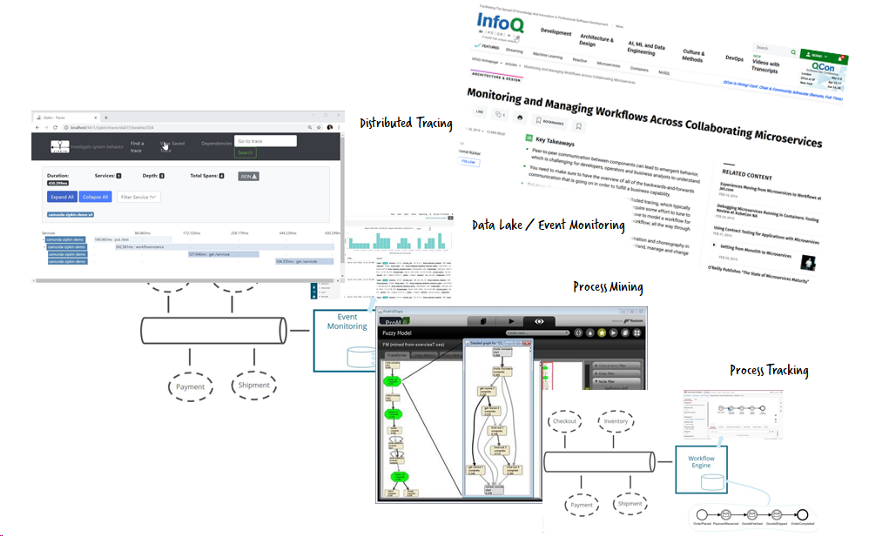
В недавней статье на InfoQ (см. “Мониторинг и управление рабочих процессов среди связанных микросервисов”) я объединил возможности вернуть немного прозрачности работе потока:
- Распределенное отслеживание (например Zipkin или Jaeger)
- Озёра данных или инструменты для аналитики (например Elastic)
- Процессная аналитика (например ProM)
- Слежка за процессами с использованием автоматизации рабочего потока (например Camunda)
В статье написано, что распределенное отслеживание является слишком техническим, теряет перспективы в бизнесе и не говорит ничего о следующих шагах в остановившемся потоке, т. е. у вас скорее всего не будет понимания на что повлияла ошибка и как возобновить работу. Elastic и схожие инструменты - это отличное решение, но требуют некоторого усилия для использования и дополнительных знаний чтобы предоставить полноценную перспективу для бизнеса. Процессная аналитика обычно фокусируется на анализе логов, а не на событийно-ориентированных архитектурах. Таким образом, дальнейшего обсуждения заслуживает только слежка за процессами.
Слежка за процессами с использованием автоматизации рабочего потока
Вы можете добавить ваш собственный компонент для чтения всех событий и поддержания определенного поведения.
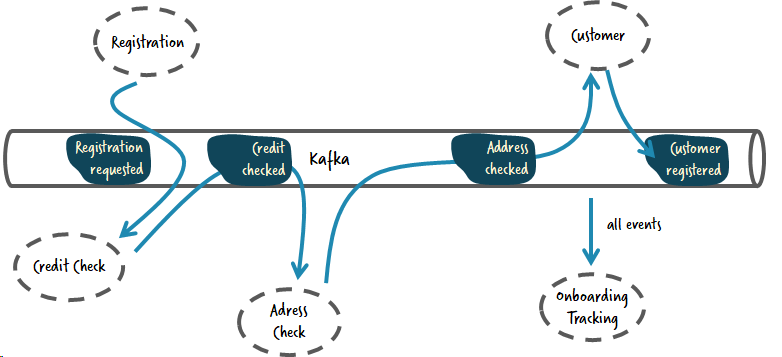
Поведение может означать “изменение состояния” отдельных сервисов.

На этом моменте скорее всего будет иметь смысл отслеживать весь поток событий.

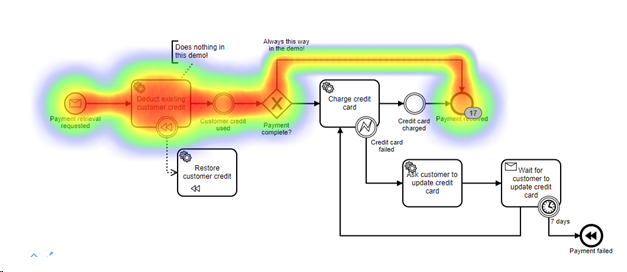
Это уже позволяет вам использовать инструменты из механизма рабочего потока для мониторинга SLA, как на примере:
Но другим отличным преимуществом слежки за процессами является возможность использования такого поведения как таймеры:
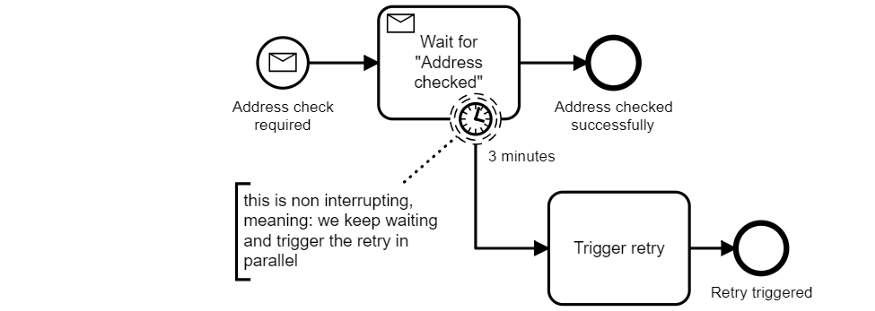
Теперь перед нами встает интересный вопрос: как запустить повтор операции? В показанной выше архитектуре это может означать повторную отправку события которое запустило поток (обязательная проверка адреса), что проблематично понять без наличия контекста.
Если мы обратим внимание на слежку за общим потоком, мы сможем понять контекст и сможем получить лучшую перспективу при повторной операции:
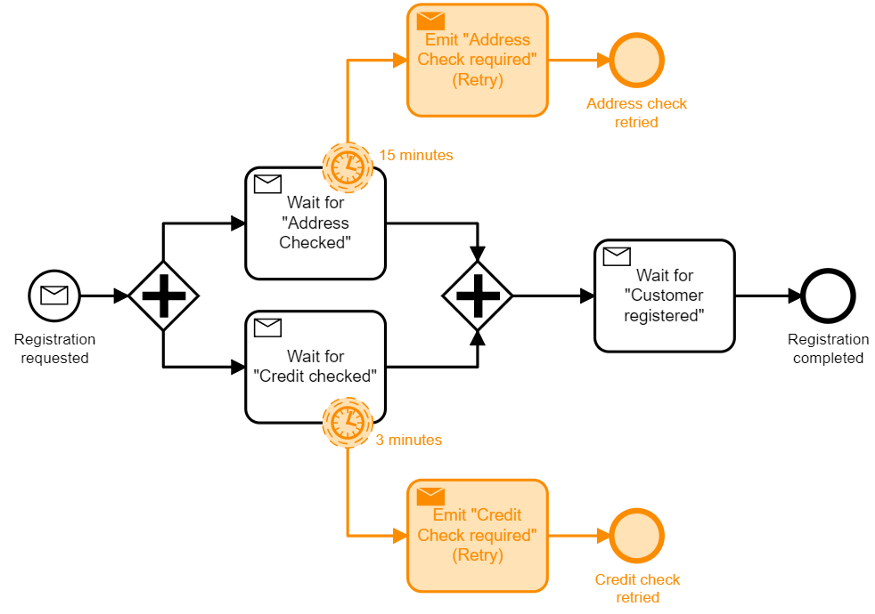
Вы можете даже добавить таймер для прерывания регистрации, если она занимает слишком много времени:
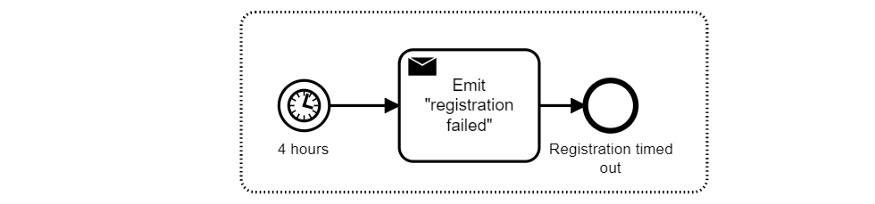
В докладе на тему слежки за процессами на Kafka Summit San Francisco 2018 (см. “Слежка и оркестрация микросервисов с Kafka и Zeebe”), я продемонстрировал конкретный пример подобного розничного процесса.
Прерывание операции может потребовать более сложной логики чем простое прекращение определенных действий. Подобный опыт был мной описан в “Сага: как реализовать сложные бизнес транзакции без обоюдного контроля завершения транзакций.”
Пока рабочий поток активно высылает события, это является мелкими шагами к оркестрации, об этом мы поговорим через секунду.
Как управлять SLA и стойкостью общего потока
Но в первую очередь давайте взглянем на управление этого потока. Кто им обладает и куда он выгружен?
Люди думают о механизмах рабочих потоков как о централизованных и тяжелых инструментах, но это не совсем так. В микросервисных архитектурах, механизмы это библиотеки используемые внутри одиночного микросервиса. (Я говорил об этом в рамках “Сложные потоки событий в распределенных системах” на QCon London; см. также “Избегая BPM монолит”).
Я дал пример (Java и Spring Boot) в моем докладе “3 частых ловушки в интеграции микросервисов”, где я использую Camunda, легкий и простой в использовании, для повторов операций с сохранением состояния (исходный код на GitHub). Нет никакой необходимости в централизации или оркестрации потоков, являющихся посторонними для вселенной микросервисов.
Чтобы определить, кто может обладать подобным потоком отслеживания, нужно найти человека в вашей организации ответственного за сквозные процессы клиентской адаптации. В вашей компании обязательно должен быть кто-то подходящий! Сотрудник желающий свободно протекающего потока, которому есть дело до SLA или до обязательных требований, и который знает сколько времени допустимо ожидать ответа для определенных операций и что произойдет при отсутствии SLA.
В нашем случае я бы либо передал эту ответственность микросервису для работы с клиентами, либо внедрил новый сервис.
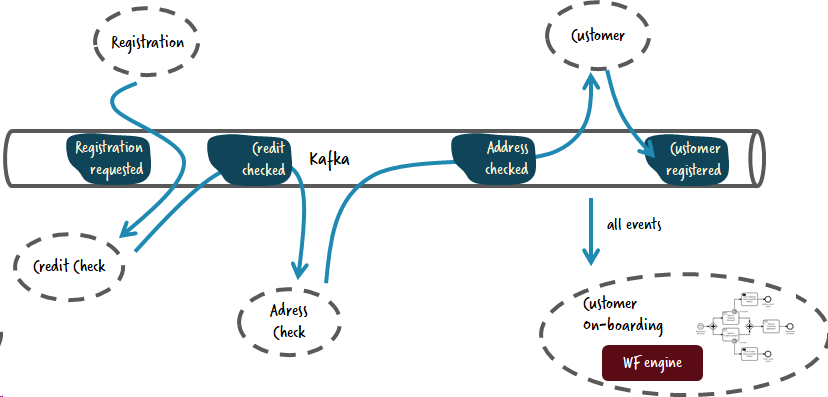
Связывание по событиям и операциям
Я бы хотел высказать еще одну важную мысль. В примере выше я использовал событие “обязательная проверка адреса”. Я постоянно вижу подобные события, но на самом деле это не событие вовсе! Это замаскированная команда. Обычно, событие дает знать кому-либо, что произошло что-либо. Это просто сообщение и нет разницы кто его получит.
Когда мы выполняем команду “обязательной проверка адреса”, вы не сообщаете о чем-то на весь мир, но то чего вы на самом деле хотите, это чтобы проверяющий адреса, проверил кое-что для вас и лучше было бы сделать это явно, через команду проверки адреса.
С моей точки зрения, команды не являются злом и не увеличивают связность. Каждая коммуникация между двумя сервисами требует некоторой степени связанности, чтобы быть эффективной. В зависимости от проблемы, возможно будет более приемлемо добавить связанность в рамках одной стороны, чем другой.
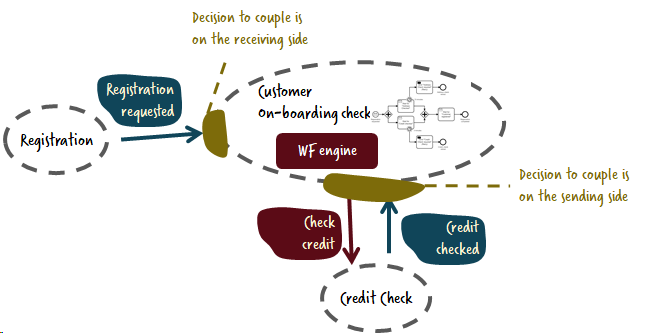
Оркестрация внутри микросервисов
Когда вы добавляете команды в сборку, рано или поздно вы придете к системе адаптации клиентов с определенной степенью логики оркестрации, но это нормально, так как этот сервис уже был ответственен за важные решения вокруг всего потока, такие как реакция на таймеры и ошибки.
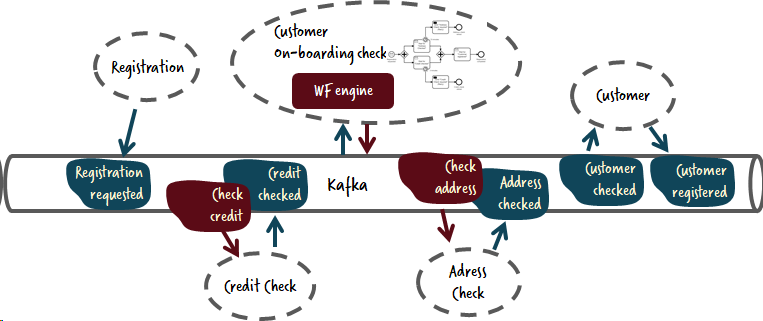
Важно понимать, что эта картина сильно отличается от того, что мы привыкли видеть в “былые” деньки SOA и BPM. В данном случае нет никакого механизма центрального потока и нет отдельной логики оркестрации. Вместо этого мы просто создаем микросервисы ответственные только за определенную логику. Иногда эта логика включает в себя поддержание состояния, как раз для таких случаев и нужен механизм рабочего потока. Иногда команды являются более чувствительным подходом к связанности, в таком случае микросервис также занимается некоторой степенью оркестрации, и вновь пример такого подхода вы можете увидеть в коде на GitHub.
Сравнение уровней связности
Давайте вернемся к изменению, когда мы внедряли дополнительную проверку на судимость с разными подходами:
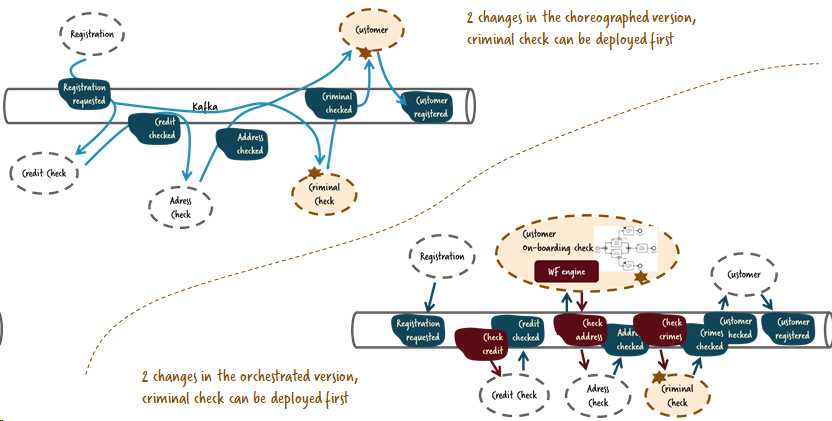
- В случае хореографии, мы можем добавить и выгрузить проверку на судимость независимо от любых других изменений, например она будет прослушивать событие “обязательной регистрации”. Результат не будет использован до того момента, пока пользовательский сервис не будет в нем нуждаться для финального решения. Это значит что сервис придется изменить и выгрузить тоже.
- В случае оркестрации, мы можем добавить и выгрузить проверку на судимость также независимо. Сервис проверки не будет знать ничего про регистрации, просто предоставьте надлежащий API и он будет готов к работе. Для того чтобы его использовать придется изменить сервис адаптации клиентов, чтобы он мог делать запросы, например через командную операцию и затем ждать события с результатом.
Изменения довольно похожи и уровень связности один и тот же. Как бонус оркестрация выглядит более натуральной, лично для меня, так как проверка на судимости скорее похожа на внутренний сервис-проводник, не обязательно имеющий доступ ко всем клиентам.
Итог
У хорошей архитектуры должен быть баланс между оркестрацией и хореографией. Этого не всегда легко добиться, особенно потому, что считается - лучше избегать оркестрации, для построения гибких систем. Но опыт с хореографией систем показывает, что их две главные проблемы: сложность понимания их поведения и сложность изменения их поведения. Я надеюсь приведенные выше примеры помогут вам понять ход моих мыслей, который до сих пор работал со многими проектами в реальной практике, с проектами основанными на современных микросервисных архитектурах.