
Статьи / Светлое будущее
30.10.2018 г., перевод статьи Ralph Kimball
Хранение данных никогда не было более ценным и интересным занятием, чем сейчас. Принятие решений на основе данных настолько фундаментально и очевидно, что нынешнее поколение бизнес-пользователей и разработчиков/конструкторов хранилищ данных не может представить себе мир без доступа к данным. Я все время подавляю в себе желание рассказывать истории о том, как это было до 1980 года.
Но это время перемен в практике хранения данных. Важно, чтобы «хранение данных» всегда охватывало сбор бизнес-потребностей и перечисление всех информационных активов организации в самом широком смысле. Если хранение данных когда-либо будет сводиться только к представлению текстовых и числовых данных из транзакционных систем записи, то будут потеряны огромные возможности.
Хранение данных определило архитектуру для публикации необходимых данных лицам, принимающим решения, и эта архитектура имеет имена: размерное моделирование, таблицы фактов, таблицы измерений, суррогатные ключи, медленно меняющиеся измерения, согласованные измерения и многое другое.
Большие изменения происходят сегодня в деловом мире: новые потоки данных из социальных сетей, бесплатные сообщения, датчики и счетчики, устройства геопозиционирования, спутники, камеры и другие записывающие устройства. Бизнес-пользователи ожидают принятия решений на основе этих источников данных. Маркетинг, традиционный двигатель хранилища данных, теперь конкурирует с производством, операциями и исследованиями. Многие из этих отделов, новички в анализе данных, строят свои собственные системы, часто подходя к этому добросовестно, но без знаний о глубоком наследии и накопленных архитектурных навыках хранения данных. Сообщество хранилищ данных должно встретиться с этими новыми бизнес-пользователями на полпути, чтобы не только предложить наши полезные перспективы, но и для того, чтобы мы больше узнали об этих новых областях бизнеса.
В этой своей статье с советами от Kimball Group по проектированию хранилищ данных, я опишу, как, на мой взгляд, меняются и будут меняться его основные компоненты в ближайшем будущем. Это захватывающее и как нельзя лучше подходящее время для того, чтобы профессионально заняться изучением и разработкой хранилищ данных!
Будущее ETL
Если хранение данных будет охватывать все активы данных организации, то оно должно иметь дело с огромными новыми потоками необычно структурированных данных. В среде ETL должно произойти несколько больших изменений.
- Во-первых, каналы данных из исходных источников должны поддерживать огромную полосу пропускания, не менее гигабайт в секунду. Ознакомьтесь с загрузкой данных в Hadoop на Sqoop... Если эти слова ничего не значат для вас, вам придется немного почитать! Начните с Википедии.
- Во-вторых, многие клиенты аналитики для этих новых потоков данных настаивают на том, чтобы никакие преобразования не применялись к входящим данным. Другими словами, участок сбора данных ETL должен иметь возможность хранить файлы, состоящие из неинтерпретированных битов, без каких-либо предположений о том, как этот файл будет храниться в базе данных или анализироваться.
- В-третьих, архитектура хранилища должна быть открытой, чтобы различные инструменты поддержки принятия решений и аналитические клиенты могли получать доступ к данным через универсальный уровень метаданных.
- В-четвертых, описания метаданных файлов данных всех типов должны быть более расширяемыми, настраиваемыми и мощными по мере появления новых сложных источников данных. Мы слишком долго работали с простыми текстовыми и числовыми файлами РСУБД, где метаданные, содержащиеся в системных файлах РСУБД, мало или вообще не имеют семантики.
Собственные стеки основных РСУБД будут разбиты на отдельные уровни хранения, метаданных и запросов. Это уже произошло в среде с открытым исходным кодом Hadoop в распределенной файловой системе Hadoop (HDFS).
Это означает, что обработка ETL в некоторых случаях может быть отложена до определенного момента времени после загрузки данных в доступные файлы. Инструменты запроса и анализа, используя метаданные, могут пожелать объявить целевую схему во время запроса как своего рода мощное «представление» во время запроса, а не во время загрузки. Как бы экзотично ни звучала эта «схема при чтении», это всего лишь еще одна форма виртуализации данных, которую мы используем уже более десяти лет. Компромисс во всех этих формах виртуализации данных заключается в том, что, заменяя вычисления реструктуризацией данных ETL, можно значительно снизить производительность. В какой-то момент после фазы исследовательского запроса разработчик, как правило, возвращается назад и выполняет обычную обработку ETL для подготовки более производительных файловых структур.
Будущее технологии баз данных
Реляционные базы данных являются основой хранилища данных и всегда будут таковыми. Но РСУБД никогда не будет расширена для обработки всех новых типов данных. Многие специализированные аналитические инструменты будут конкурировать друг с другом для анализа данных и корректно сосуществовать с базами данных РСУБД, которые будут выбирать части входящих потоков данных, обрабатываемых реляционными базами данных.
По смежной теме архивирования. Оно никогда не будет прежним. Дисковое хранилище выиграло войну за долгосрочный выбор архивирования по многим причинам, но самым большим фактором является удивительная низкая стоимость за петабайт. Кроме того, дисковое хранилище всегда находится в оперативном режиме, поэтому архивные данные остаются активными и доступными, ожидая новых режимов анализа и новых ретроспективных запросов. Это называется «активным архивированием».
Будущее размерного моделирования
Даже в дивном новом мире незнакомых типов данных и нереляционной обработки, размерное моделирование чрезвычайно актуально. Даже самые причудливые типы данных можно рассматривать как набор наблюдений, записанных в реальном мире. У этих наблюдений всегда есть контекст: дата, время, местоположение, клиент/человек/пациент, действие – список можно продолжать бесконечно. Это, конечно, наши привычные измерения. Когда мы это осознаем, внезапно появляется вся знакомая размерная техника. Мы можем прикрепить наши высококачественные измерения из EDW к любому источнику данных. Раздвиньте границы своего сознания: это объединение не обязательно должно быть выполнено через обычное объединение реляционных баз данных, потому что может быть сделано другими способами.
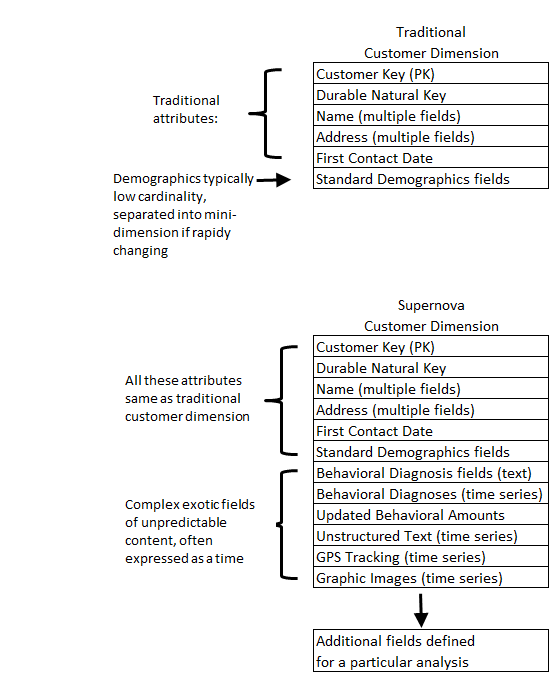
Измерения – это, несомненно, душа хранилища данных. Факты – это просто наблюдения, которые всегда существуют в пространственном контексте. В дальнейшем мы можем ожидать, что измерения станут более мощными для поддержки более сложных запросов на основе поведения и прогнозной аналитики. Уже есть предложения по обобщению схемы звезды в схему Supernova. В схеме Supernova размерные атрибуты могут стать сложными объектами, а не простым текстом. Измерения в Supernova также становятся более гибкими и расширяемыми от одного анализа к другому. Сравните традиционное измерение клиента с измерением клиента в Supernova на рисунке ниже. Обратите внимание, что это не какой то недостижимый журавль в небе, а доступная технология. Сегодня можно обобщить один атрибут измерения с помощью массива структур. Пора прочитать справочное руководство по SQL.
Будущее инструментов BI
Пространство средств бизнес-аналитики будет расти и станет включать в себя много других, отличных от SQL, видов анализа. Конечно, это уже произошло, особенно в среде Hadoop с открытым исходным кодом, и мы всегда полагались на мощные инструменты, отличные от SQL, такие как SAS. Таким образом, в некотором смысле, это вопрос определения того, что является инструментом BI. Я считаю, что этот момент главным образом заключается в том, чтобы команды хранилища данных могли расширять сферу охвата и не упускали из вида новые источники данных и новые виды анализа.
Будущее профессионалов в области хранилища данных
Я много раз отмечал, что успешный специалист по хранилищу данных должен интересоваться тремя вещами: бизнесом, технологиями и бизнес-пользователями. Это всегда будет также верно и в будущем. Если вы хотите тратить свое время на кодинг и не разговаривать с бизнес-пользователями, это здорово, но тогда вы не принадлежите к команде хранилища данных. Было сказано, что профессионалы в области хранилища данных в будущем должны обладать навыками Unix и Java, а также быть знакомы с некоторыми из основных аналитических сред, отличных от SQL, таких как Spark, MongoDB и HBase, а также с инструментами передачи данных, такими как Sqoop.
Я думаю, что важнейшая задача в будущем – это распространение среди как можно большего количества людей описания работы специалистов хранилища данных. Внезапно появляются новые отделы, которые пытаются справиться с потоками данных и, вероятно, изобретают колесо, в виде хранилища данных. Выясните, что это за отделы, и расскажите им о силе согласованных измерений и суррогатных ключей. Предложите взаимовыгодное сотрудничество на базе EDW.
И, как говорит Марджи: идите вперед и будьте размерными.